
안녕하세요. 오늘은 코드로 알아보는 java 시간압니다. 오늘 여러분들과 알아볼 Java의 자료구조는 PriorityQueue입니다. PriorityQueue는 우선순위 큐입니다. 우선순위 큐는 일반적인 FIFO 구조를 가지는 큐에 우선순위를 넣어 우선순위가 높은 노드부터 먼저가져올 수 있는 Queue입니다.
Heap 자료구조
PriorityQueue는 Heap 자료구조를 기반으로 되어있습니다. 먼저 Heap 자료구조란 무엇인지를 확인해보겠습니다. Heap 자료구조는 최솟값, 최댓값을 빠르게 찾기위해 완전 이진 트리를 사용하는 자료구조입니다. 간단히 개념을 설명드리면 최소힙의 경우 root 노드가 값이 제일 작으며 트리는 부모 노드는 자식 노드보다 값이 작음을 항상 만족하는 트리입니다. 그리고 이렇게 Heap 자료구조를 맞추는 힙 생성 알고리즘을 Heapify 알고리즘이라고 합니다.

삽입
최소힙을 기준으로 힙자료구조에 데이터를 넣어보도록 하겠습니다. 데이터를 넣으면 Heap 자료구조를 유지하기 위한 힙생성 알고리즘이 시작됩니다. 먼저 마지막 인덱스에 노드를 삽입합니다.

삽입된 노드의 값과 그 부모노드의 값을 비교하여 더 작은 값을 부모노드로 합니다. 여기서는 삽입된 노드의 값이 부모 노드의 값보다 작으므로 둘을 교환합니다. 교환 완료 후 그 부모 노드와도 비교를 다시 시작합니다.

부모 노드의 값은 1이고 현재 노드의 값은 4이므로 부모노드의 값이 더 작습니다. 따라서 교환할 필요가 없습니다.
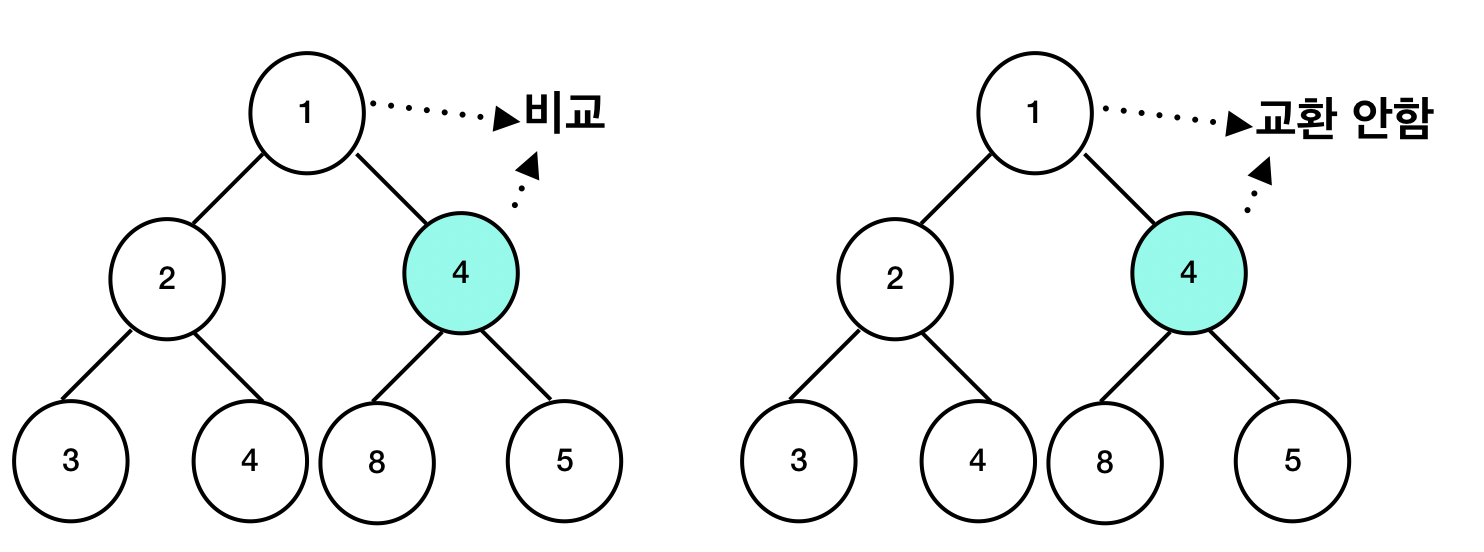
삭제
힙의 노드 삭제는 일반적으로 root에서 일어납니다. root 노드의 값을 삭제하도록 해보겠습니다. 삭제할 노드인 1과 마지막 노드 8을 교환합니다.
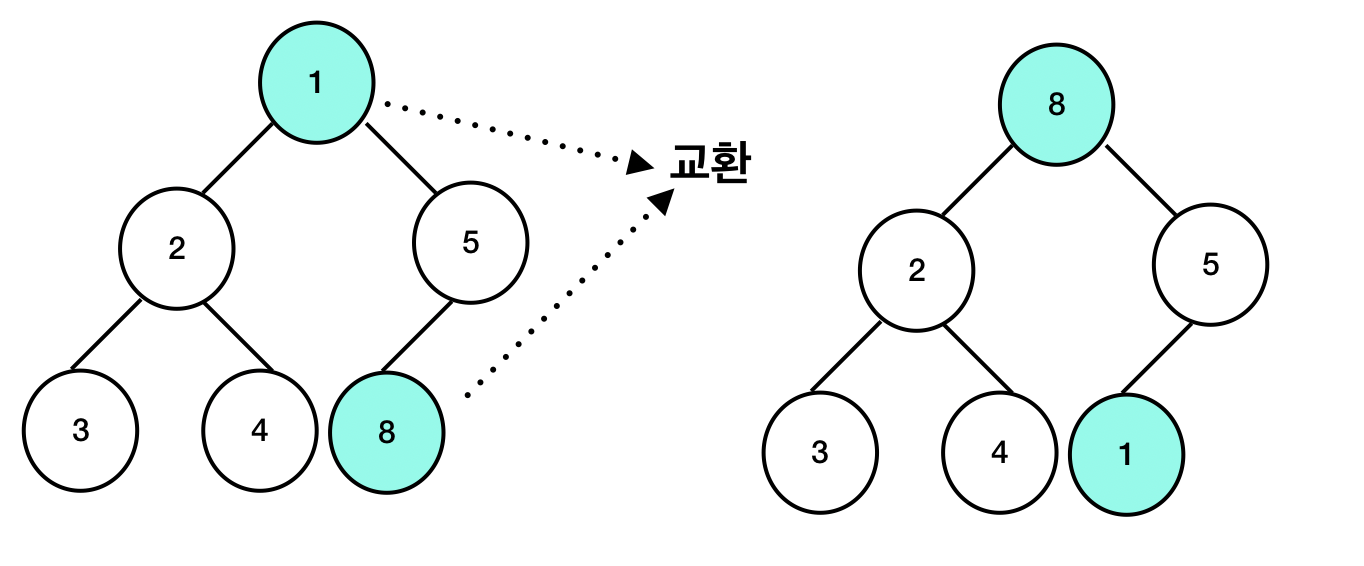
교환 후 삭제할 노드인 1은 null로 치환하는 등의 조치를 취하여 트리에서 제외시킵니다. 힙 생성 알고리즘을 실행합니다. 먼저 root 노드의 8과 자식 노드인 2와 5를 비교합니다. 최소힙이기 때문에 자식 노드 중 더 작은 값인 2와 교환을 진행합니다. 교환을 진행 한 후 힙 생성 알고리즘을 다시 반복합니다. 그러면 이번에는 3 노드와 교환될 것입니다.

Priority Queue
그럼 이제 Java에서 구현하고 있는 우선순위 큐 (Priority Queue)에 대해서 알아보도록 하겠습니다. 사용방법은 아래와 같습니다.
public void priorityQueueTest() {
Queue<Integer> queue = new PriorityQueue<>();
queue.add(2);
queue.add(3);
queue.add(7);
queue.add(1);
int size = queue.size();
for (int i = 0 ; i < size; i++) {
System.out.println("poll " + i + " : " + queue.poll());
// 1, 2, 3 7
}
}기본적으로 우선순위가 낮은 수 부터 출력되는 것을 알 수 있습니다. 우선순위를 오름차순으로 하기 위해서는 아래와 같이 선언하면 됩니다.
Queue<Integer> queue = new PriorityQueue<>(Collections.reverseOrder());자 이제 본격적으로 PriorityQueue의 내부 구조를 알아보도록 하겠습니다.
클래스 상속 구조
PriorityQueue의 상속 구조입니다. AbstractQueue를 상속받고 있습니다. AbstractQueue를 들어가보면 인터페이스 Queue와 추상 클래스 AbstractCollection을 상속받고 있다는 사실을 알 수 있었습니다.
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {내부 변수
내부 변수를 보고 PriorityQueue는 내부에 힙 자료구조를 구현하고 있다는 사실을 알 수 있었습니다. 그리고 그 구현은 Object 배열을 통해 이루어지는 것을 알 수 있습니다. queue 변수의 상단에 있는 문장을 보면 확실히 알 수 있었습니다. 아래는 그 문장을 제 나름대로 번역해놓았습니다. comparator의 값은 정렬의 기준이 되는 값입니다.
/**
* 우선순위 큐는 균형잡힌 이진 힙으로 표현됩니다. queue[n]의 자식 노드는
* queue[2*n+1]와 queue[2*(n+1)] 두개입니다.우선순위 큐는 comparator 값
* 또는 엘리먼트의 값을 기준(compartor가 null 일경우)으로 정렬되어집니다. 가장
* 작은 값을 가지는 노드는 queue[0]입니다.
*/
transient Object[] queue;
int size;
private final Comparator<? super E> comparator;생성자
PriorityQueue의 생성자는 파라미터가 없는 생성자, initialCapacity만 가지는 생성자, 그리고 comparator를 호출하는 생성자도 있지만 결국 세가지 생성자 모두 아래의 생성자를 호출합니다. 따라서 아래의 생성자만 보도록 하겠습니다. 생성자에서는 queue의 Object 배열을 초기화하고 비교의 키를 설정하는 것을 알 수 있었습니다.
/**
* @param initialCapacity queue 변수의 초기화 배열 크기
* @param comparator 순서 정렬에 사용할 값. 만약 null이라면 엘레멘트의 기본값(equals)기반으로 정렬됨
* @throws IllegalArgumentException 만약 {@code initialCapacity}가 1보다 작으면 반환
*/
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}데이터 신규 추가
그럼 이제 실질적으로 데이터를 삽입시 일어나는 로직을 알아보도록 하겠습니다. PriorityQueue는 AbstractCollection을 상속받고 있기때문에 add 메서드가 있습니다. 하지만 add의 경우 offer 메서드에 위임하는 역할밖에 하지 않으므로 offer 메서드를 보도록 하겠습니다. 아래의 코드를 통해 Array의 마지막 index에 데이터를 넣은 후 Heapify를 진행하는것을 알 수 있습니다.
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1); // 크기가 queue의 배열 크기를 넘었을 경우 queue 크기 재산정
siftUp(i, e);
size = i + 1;
return true;
}
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// queue의 기존 크기가 64보다 작으면 2증가 크면 2배 증가
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// MAX_ARRAY_SIZE(Integer의 MAX 값 - 8)를 초과했을때 OOM 체크
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
/**
* Item x를 position k에 넣는 메서드, 넣은 후 heapify를 진행한다.
*
* @param k 데이터를 Array에 넣는 위치
* @param x 넣는 데이터 값
*/
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x, queue, comparator);
else
siftUpComparable(k, x, queue);
}
private static <T> void siftUpUsingComparator(
int k, T x, Object[] es, Comparator<? super T> cmp) {
while (k > 0) { // 루트까지 반복
int parent = (k - 1) >>> 1; // 부모노드는 queue[(k - 1)/2] 값
Object e = es[parent];
if (cmp.compare(x, (T) e) >= 0) // 부모값과 비교하여 더 크다면
break;
es[k] = e;
k = parent;
}
es[k] = x;
}
private static <T> void siftUpComparable(int k, T x, Object[] es) {
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = es[parent];
if (key.compareTo((T) e) >= 0)
break;
es[k] = e;
k = parent;
}
es[k] = key;
}데이터 가져오기
일반적인 Queue의 poll은 가장 먼저들어온 값을 반환하도록 되어있습니다. 그러나 PriorityQueue는 우선순위가 가장 높은 값을 반환하는 하도록 되어있습니다. 코드로 PriorityQueue의 poll 메서드를 한번 보도록 하겠습니다. root 값은 반환되어 사라지며 마지막 노드의 값을 root로 올려 아래의 값들과 비교하며 heapify를 재구성하는 것을 알 수 있습니다.
public E poll() {
final Object[] es;
final E result;
if ((result = (E) ((es = queue)[0])) != null) { // root Node를 검사 null이 아닐 경우
modCount++;
final int n;
final E x = (E) es[(n = --size)]; // 마지막 노드를 가져옴
es[n] = null;
if (n > 0) {
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
siftDownComparable(0, x, es, n); // 마지막 노드를 0번째 노드로 옮기고 비교하는 것 처림 만듬
else
siftDownUsingComparator(0, x, es, n, cmp);
}
}
return result;
}
private static <T> void siftDownComparable(int k, T x, Object[] es, int n) {
// assert n > 0;
Comparable<? super T> key = (Comparable<? super T>)x;
int half = n >>> 1; // 마지막 노드까지 길이, 최대 N / 2번 비교
while (k < half) {
int child = (k << 1) + 1; // 왼쪽 노드
Object c = es[child];
int right = child + 1; // 오른쪽 노드
if (right < n &&
((Comparable<? super T>) c).compareTo((T) es[right]) > 0)
c = es[child = right]; // 왼쪽노드, 오른쪽노드를 비교하여 더 작은값을 반영
if (key.compareTo((T) c) <= 0) // heapify 중인 값이 더 작으면 멈춤 그렇지 않다면 교환
break;
es[k] = c;
k = child;
}
es[k] = key;
}
private static <T> void siftDownUsingComparator(
int k, T x, Object[] es, int n, Comparator<? super T> cmp) {
// assert n > 0;
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = es[child];
int right = child + 1;
if (right < n && cmp.compare((T) c, (T) es[right]) > 0)
c = es[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
es[k] = c;
k = child;
}
es[k] = x;
}순환
마지막으로 priorityQueue를 forEach로 순화하면 어떻게 값이 나오는지 보도록 하겠습니다. 순환은 단순합니다. queue는 array로 되어있고 이를 0번 부터 마지막 인덱스까지 순환하는 것을 아래의 코드를 통해 알 수 있었습니다. 이렇게 순환했을 때 우선순위에 따라서 노출될까요? 정답은 그렇지 않습니다. 힙 자료구조는 같은 형제 노드라고 할때 왼쪽의 값 오른쪽보다 무조건 더 크지 않습니다. 따라서 이는 만족되지 않습니다.
/**
* @throws NullPointerException {@inheritDoc}
*/
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
final Object[] es = queue;
for (int i = 0, n = size; i < n; i++)
action.accept((E) es[i]);
if (expectedModCount != modCount)
throw new ConcurrentModificationException();
}
public void priorityQueueTest() {
Queue<Integer> queue = new PriorityQueue<>();
queue.add(2);
queue.add(3);
queue.add(7);
queue.add(1);
int size = queue.size();
queue.forEach({ element ->
// println 시 1, 2, 7, 3 노출
})
}마무리
오늘은 이렇게 Java의 PriorityQueue와 Heap 자료구조에 대해서 알아보는 시간을 가져보았습니다.
다음시간에도 더 재미있는 주제로 찾아뵙도록 하겠습니다.
감사합니다.
참조
'기타 > 자료구조' 카테고리의 다른 글
| 우선순위 큐(Heap)과 트리맵(Red black Tree)의 차이 (2) | 2021.02.18 |
|---|---|
| [자료구조] 코드로 알아보는 java의 TreeMap (0) | 2021.01.20 |
| [자료구조] 코드로 알아보는 java의 EnumMap (0) | 2020.12.06 |
| [자료구조] 코드로 알아보는 java의 LinkedHashMap (0) | 2020.10.19 |
| [자료구조] 코드로 알아보는 java의 HashSet (0) | 2020.02.17 |




댓글