
Java에서는 다양한 방법으로 병렬 처리를 만들 수 있습니다. 기본적인 Thread 클래스를 이용할 수 있으며, ExecutorService를 이용하여 쓰레드풀도 쉽게 만들 수 있습니다. 그리고 CompleteFuture를 이용하면 쓰레드 간의 데이터 동기화, 실행 순서 등도 원하는 대로 조작할 수도 있습니다.
그리고 Java8애서 등장한 Stream은 병렬 처리를 쉽게 사용할 수 있게 메서드를 제공해줍니다. 만들어 놓은 Stream에 parallel를 추가하기만 하면 되죠.
오늘은 java8의 병렬 Stream에 대해서 알아보는 시간을 가져보겠습니다.
Stream 예제
오늘 사용할 예제는 아래와 같습니다.
코드에는 java google style guide를 적용하였습니다.
메서드를 하나 만들도록 하겠습니다. 해당 메서드는 이름을 파라미터로 받습니다. 메서드는 Person 객체를 만듭니다. Person 객체에는 name과 age가 필요합니다. name은 파라미터로 받기 때문에 괜찮지만 age는 외부 API를 통해서 가져와야합니다. 여기서는 간단히 3초의 delay 시간을 주고 Random하게 뽑아내는 것으로 하겠습니다. 이렇게 Name과 age를 통해 Person 객체의 List를 반환하는 것이 해당 메서드입니다.
로직을 구현하기 위해서 먼저 Person 객체를 만듭니다. Person 객체는 name을 파라미터로 받는 생성자를 통해 만들 수 있습니다. 그리고 나이를 update하는 updateAge라는 객체를 만들었습니다. 각 맴버변수를 반환하는 get Method와 객체의 내용을 출력하는 toString 메서드도 있습니다.
public class Person {
private String name;
private Integer age;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public Person updateAge(Integer age) {
this.age = age;
return this;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}아래는 Stream을 통해 Person 객체를 만들고 각각을 출력하는 클래스입니다. @Test가 붙은 메서드를 Client 메서드라고 생각해주시면 됩니다. createPerson 메서드에 로직이 들어가 있습니다. 해당 메서드를 보시면 Person 객체를 이름을 통해 먼저 만들고 이름을 통해 findAge 메서드를 통해 가져온 age값을 Person 객체의 age로 넣습니다. 그리고 결과를 List<Person>으로 반환해주고 있습니다.
public class StreamSample {
private Random ageRandom = new Random();
@Test
public void Test() {
List<Person> person = createPerson(
Arrays.asList("Jhon", "Yeom", "Takenaka", "Hikari"));
person.forEach(System.out::println);
}
public List<Person> createPerson(List<String> names) {
return names.stream()
.map(Person::new)
.map(person -> person.updateAge(findAge(person.getName())))
.collect(Collectors.toList());
}
public Integer findAge(String name) {
Integer age = ageRandom.nextInt(name.length() * 3) + 1;
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException ignore) {
}
return age;
}
}위 테스트를 진행했을때 4개의 Element에 대해서 각각 3초의 시간이 소모되므로 아래와 같은 결과를 얻을 수 있었습니다.
# 테스트 경과 시간 : 12.197초
Person{name='Jhon', age=7}
Person{name='Yeom', age=7}
Person{name='Takenaka', age=15}
Person{name='Hikari', age=16}이런 결과를 얻은 것을 병렬 스트림을 통해 시간을 줄여보도록 하겠습니다.
병렬 Stream
해당 스트림을 병렬 스트림으로 변경해보도록 하겠습니다. 정말 쉽습니다. 아래 처럼 stream으로 변경 후 parallel 메서드를 붙여주기만 하면 됩니다. 이렇게 하면 병렬 처리가 이루어집니다.
public List<Person> createPerson(List<String> names) {
return names.stream()
.parallel() // 추가된 곳
.map(Person::new)
.map(person -> person.updateAge(findAge(person.getName())))
.collect(Collectors.toList());
}바로 테스트 결과를 보도록 하겠습니다.
# 테스트 경과 시간 : 3.197초
Person{name='Jhon', age=2}
Person{name='Yeom', age=6}
Person{name='Takenaka', age=19}
Person{name='Hikari', age=1}이렇게 모두가 행복하게 끝났습니다 ! 라고 마무리하면 좋았겠지만... 조금 더 생각해 봐야할 부분이 있습니다. 우리가 실 운영에서 이렇게 모든 Stream을 병렬 스트림으로 변경한다고 하면 정말 큰일이 날 수 있습니다.
Stream의 parallel에 대해서 좀 더 깊게 알아보도록 하겠습니다.
내부 로직 파악
병렬 Stream은 내부적으로 Java 7에 추가된 Fork / Join Framework를 사용합니다. Fork / Join Framework은 작업을 분할가능할 만큼 쪼개고 쪼개진 작업을 별도의 work thread를 통해 작업후 결과를 합치는 과정을 거쳐 결과를 만들어냅니다.
그리고 병렬 스트림의 Fork/Join Framework의 work Thread의 수는 서비스가 돌아가는 서버의 CPU 코어 수에 종속됩니다. 즉 개인 PC에서 돌렸을 때 4Core PC라면 thread는 4개로 작업을 진행합니다. Java에서는 Runtime.getRuntime().availableProcessors()으로 CPU Core 숫자가 확인 가능합니다. 제가 테스트한 PC의 코어수는 4개 였습니다. 함께 살펴본 병렬화 예제에서는 name의 List가 4개 였습니다. 그리고 결과가 3초로 나왔지만 만약 5개로 테스트했을 때는 6초의 결과를 얻을 수 있음을 예상할 수 있고 실제로 그렇게 결과가 나왔습니다.
병렬 Stream Fork/Join Framework의 ThreadPool의 크기는 조정이 가능합니다. System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "20")의 값을 변경해주면 됩니다. 이렇게 하면 threadPool의 크기를 변경할 수 있습니다.
병렬 Stream의 가장 큰 문제는 threadPool을 global하게 이용한다는 것입니다. 즉, 모든 병렬 Stream이 동일한 ThreadPool에서 thread를 가져와 사용합니다. 이렇게 되면 Thread Pool의 문제점이 발생할 수 있습니다. 잠깐 Thread Pool을 사용할 때의 주의사항을 한번 보고 가도록 하겠습니다.
Thread Pool 사용의 주의사항
Thread Pool은 무분별하게 Thread의 수가 늘어나는것을 막아줍니다. 필요할 때 빌려주고 사용하지 않으면 반납하여 Thread의 숫자를 유지하는 역할을 합니다. 그런데 만약 Thread를 사용중인 곳에서 아래 이미지 처럼 Thread를 반납하지 않고 계속 점유중이라면 어떻게 될까요?
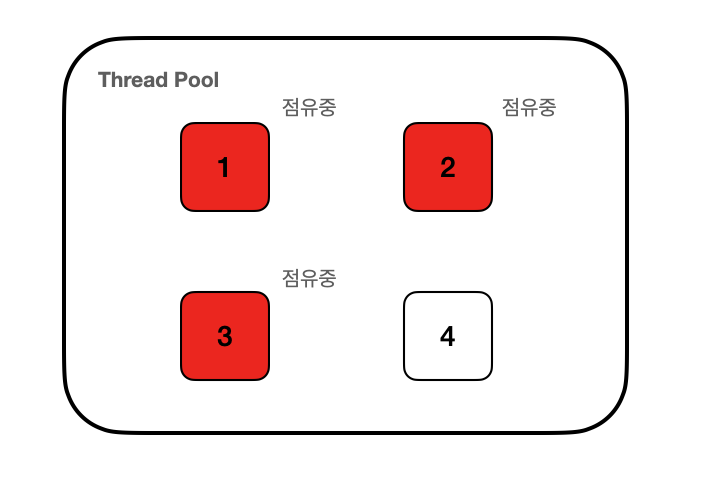
이렇게 되면 Thread 1,2,3은 사용할 수 없으며 Thread 4 한개만을 이용해서 모든 요청을 처리하게 됩니다. 특히, Thread 1, 2, 3이 sleep과 같이 아무런 일을 하지 않으면서 점유를 하고 있다면 이는 문제가 큽니다. 만약 Thread 4까지 점유중이게 되면 더이상 요청은 처리되지 않고 Thread Pool Queue에 쌓이게 되며 일정치 이상이 되면 요청이 drop 되는 현상까지 발생할 것입니다.
이러한 Thread Pool을 사용할 때 주의해야할 점은 병렬 Stream을 사용할 경우에도 동일하게 적용됩니다. ForkJoinPool을 서비스의 global하게 적용되기 때문에 만약 A 메서드에서 4개의 thread를 모두 점유하면 다른 병렬 Stream의 요청은 처리되지 않고 대기하게 됩니다.
커스텀 ForkJoinPool을 이용한 병렬 스트림
이러한 문제점은 ForkJoinPool을 커스텀하게 제작함으로써 해결할 수 있습니다. 아래 코드는 위 예제에서 createPerson 메서드를 커스텀 ForkJoinPool을 사용하도록 변경한 예제입니다. 아래 예제의 결과 3초의 시간이 걸리는 것으로 적용된 것을 알 수 있었습니다.
ForkJoinPool은 ExecutorService를 AbstractExecutorService를 통해서 상속받고 있습니다. 따라서 `` ExecutorService를 사용하듯이 사용해주면 됩니다. ExecutorService를 이용하는 법은 이전의 [Java8] Java 비동기 - CompletableFuture 에서 자세히 다뤘었으므로 참고 부탁드립니다.
public List<Person> createPerson(List<String> names)
throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool(5);
return forkJoinPool.submit(() -> {
return names.stream()
.parallel()
.map(Person::new)
.map(person -> person.updateAge(findAge(person.getName())))
.collect(Collectors.toList());
}).get();
}마무리
오늘은 이렇게 Java8의 비동기 Stream에 대해서 알아보는 시간을 가졌습니다.
감사합니다.
참조
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html
모던 자바 인 액션 (7장)
'language, framework, library > Java' 카테고리의 다른 글
| [Java] Java 제네릭의 형 변환(covariant & contravariant) (0) | 2020.11.11 |
|---|---|
| [java] 배열(Array)과 컬렉션 제네릭의 차이 (0) | 2020.11.08 |
| [Java9] Reactive Stream Flow - Processor 실습 (0) | 2020.07.17 |
| [Java9] Reactive Stream Flow - 실습편 (0) | 2020.07.15 |
| [Java8] Java 비동기 - CompletableFuture (0) | 2020.07.11 |




댓글